
2015年《中国本土化
2015年《中国本土化催眠》心理治疗技能班(29期) 海口站 最适合中国大陆人的催眠技…
可是你或许会接着说,这个结果并不代表「相似的伴侣比互补的伴侣优」啊!没错,或许会让你大失所望的是,这问题在会议当场并没有被提出来--因为古早的时候这些做初始关系的人就吵过了:虽然相似和互补各有各的重要性,但长期来说,与相似的伴侣在一起,还是比互补的伴侣摩擦来的少,而且,更重要的是「你觉得」对方跟你像不像,而不是「实际上」对方跟你像不像(Lutz-Zois, Bradley, Mihalik, & Moorman-Eavers, 2006)。跟「你觉得像」的人在一起你会感到比较多幸福,而这种幸福感又会回过头来让你觉得你跟他越来越像(Morry, Kito, & Ortiz, 2011)。
总之,支持「互补」这一派人马就会泪眼汪汪地跟「相似」说:「魔王,你赢了」[3]。但如果你发挥柯南精神,你会发现上面Dijkstra & Barelds的研究有一个地方好像怪怪的--大家的人格特质都不一样,那和自己相似的「那个人」不是也会不一样吗?那我们如何喜欢「和自己相似」的人,又在寻找「同一个」人呢?其实,这牵涉到「相似」的计算方法。
秘密二:“契合度”究竟是怎么算的
这个部份需要花一点脑,如果你现在大脑跟牛仔一样忙,可以先跳过这段中间直接看结论。过去研究计算相似性,大都是采用两种方法[4]:
(1)以Profile Similarity的方式来看人格特质的相关程度。简单地说,假设你在人格量表上1到5题的得分是5,5,1,4,1,小花也是5,5,1,4,1,那么你跟小花简直是天作之合--至少比得分是5,5,1,4,2的小熊适合你,因为你和小花比较「像」--而得分是1,1,5,2,5的小坚则完全不适合你,因为你跟他实在「太不像」了(图一)。这类的计算方法在乎的是「整体起伏」的相似,他高你也高,你低他也低,那么你们就是彼此的真命天子或天女。
(2)以Difference Score的方式来看两者的差距,也就是把两个人的分数相减,取绝对值。同样的例子,假设你在人格量表上1到5题的得分是5,5,1,4,1,你和小花的差距就是0,和小熊的差距是1,和小坚的差距是18。你看,小坚果然很不适合你!这类的方法在乎的是程度,也就是你在某项特质的得分多寡。
一言以蔽之,我们一方面可以藉由Profile Similarity得分较高,或是Difference Score差距较小,找出和你相似的人,也另一方面可以单纯计算「你觉得理想的情人应该具备哪些特质?」,找出得分最高,大家都重视的特质。这样,Dijkstra & Barelds研究所说的:「大家都在找同一种人,但也在找与自己相似的人」的说法就可以说得通了--只是用不同观点看同一份数据而已。
类似这样的方法,甚至一直到近几年的美国社会心理学年会中都还在延用,用来预测之后这个人会不会跟你在一起、你们会不会互相吸引(Luo, 2009)、在一起之后,相似的人就比较幸福吗等等(Cheng & Chen, 2009)--遗憾地是这两种方法都有问题。
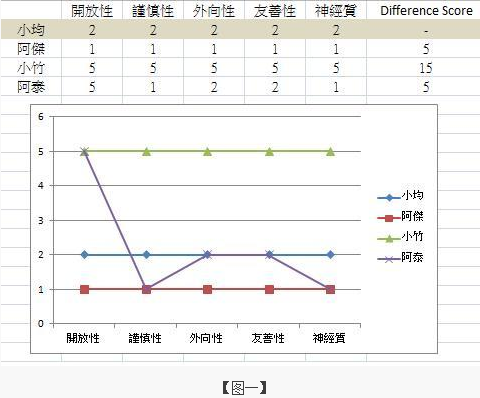
小均的难题
举例来说,倘若今天小均做完测验得分是2,2,2,2,2,揪竟是得分1,1,1,1,1的阿杰,还是5,5,5,5,5的小竹是她的真命天子呢?Dr. Profile Similarity会预测这两个人都一样适合她,但是Dr. Difference Score会说:「傻瓜阿你,当然是阿杰阿!因为和阿杰差距是5,和小竹的差距是15耶!」。这样看起来,似乎Difference Score的方法区辨力较佳,略胜一筹。
但是如果今天半路杀出了5,1,2,2,1分的阿泰(差距也是5),那他要选谁呢?当Dr. Difference Score在苦恼时,Dr. Profile Similarity就可以神气地说:「当然是阿杰阿!因为图型的pattern比较像。」(请见图一)



